部署LLaMA2
本案例以 “LLaMA2” 为例,指导如何在平台的开发环境中部署 LLaMA2。
LLaMA 2,是 Meta AI 正式发布的最新一代开源大语言模型。根据其参数量级,LLaMA2 系列共开放了 6 个模型供大家使用,分别为基础模型 llama-2-7B、llama-2-13B、llama-2-70B 和已经过微调的对话模型 llama-2-7B-chat、llama-2-13B-chat、llama-2-70B-chat。更多关于 LLaMA 2 的详细信息请阅读 LLaMA 2 官方 (opens new window)。
# 准备代码&模型
代码获取。
- 方式一:单击 链接 (opens new window) 直接下载代码。
说明:该方式同官方获取的代码一致,为了节约您的时间,提前从官方
git clone好并打包的。 - 方式二:通过如下 git 指令从官方获取。clone 的代码目录名为
git clone -b llama_v2 https://github.com/facebookresearch/llama.gitllama,为方便您后续命令可直接复制执行,建议修改为llama2后再打包上传到平台。
- 方式一:单击 链接 (opens new window) 直接下载代码。
模型文件获取。
已在平台中为您预置了本次体验所需的 llama-2-7B、llama-2-7B-chat 模型文件,创建项目时可直接挂载。
其他量级的模型可参考 模型获取 从官方获取,也可使用平台中 “趋动云小助手” 提供的公开模型。
# 创建项目
单击平台项目页右上角的 创建项目,随后在弹框中配置项目的基本信息。
- 项目名称:可自定义,如 “LLaMA2 部署”。
- 项目描述:如 “部署LLaMA2并体验与其对话”。
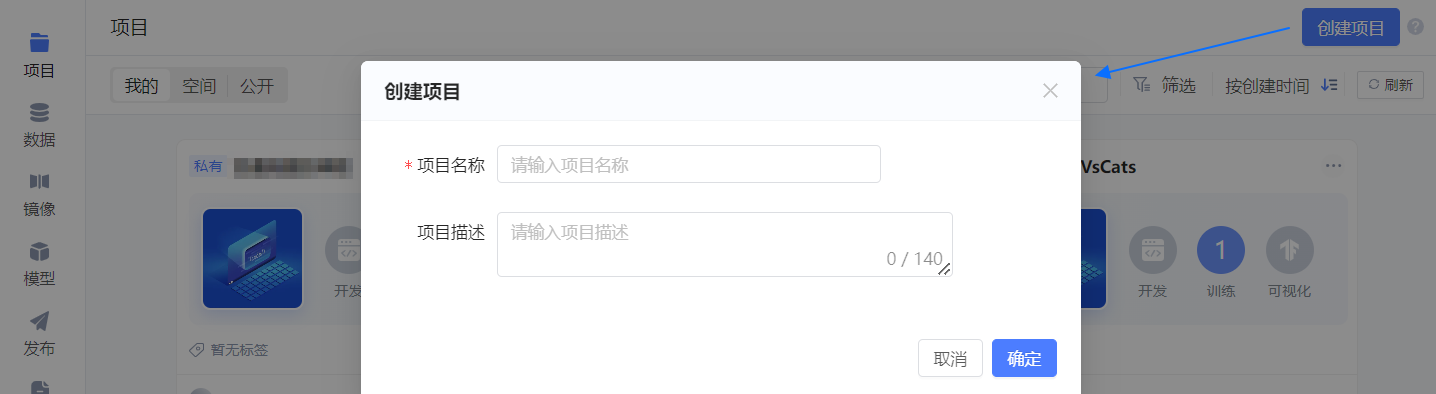
单击 确定,项目创建成功,并进入 初始化开发环境 引导页。
在 初始化开发环境 页中配置如下信息,其他参数保持默认值。
- 资源配置:选择 高级版 中 P1.large。
- 镜像:选择 官方 镜像 PyTorch 2.0.0(PyTorch1.10以上的镜像均可)。
- 模型:选择 公开 下的 llama-2-7b 和 llama-2-7b-chat(作者均为“趋动云小助手”)。
- 自动停止(高级设置 中):选择 8小时。
资源配置说明: Llama2 全量数据共 300G 多,包含 7B、13B、70B 参数量级的模型, 实例配置建议:
- 7B, 单卡,每卡显存 >20G,建议规格 P1.large。
- 13B,两卡,每卡显存 >20G,建议规格 P1.2xlarge。
- 70B,八卡,每卡显存 >20G,建议规格 P1.8xlarge。
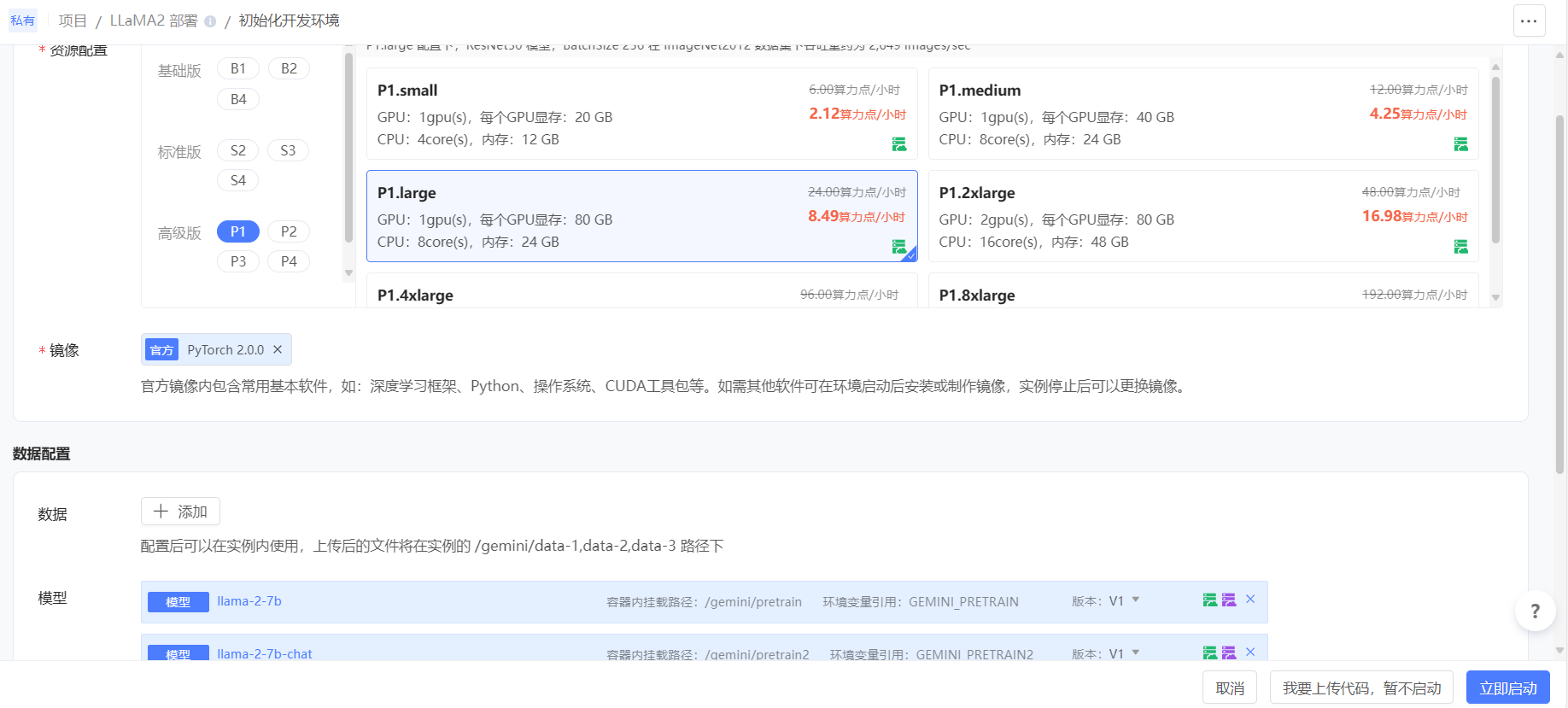
随后单击右下角 我要上传代码,暂不启动,进入 项目代码 页。
# 上传代码
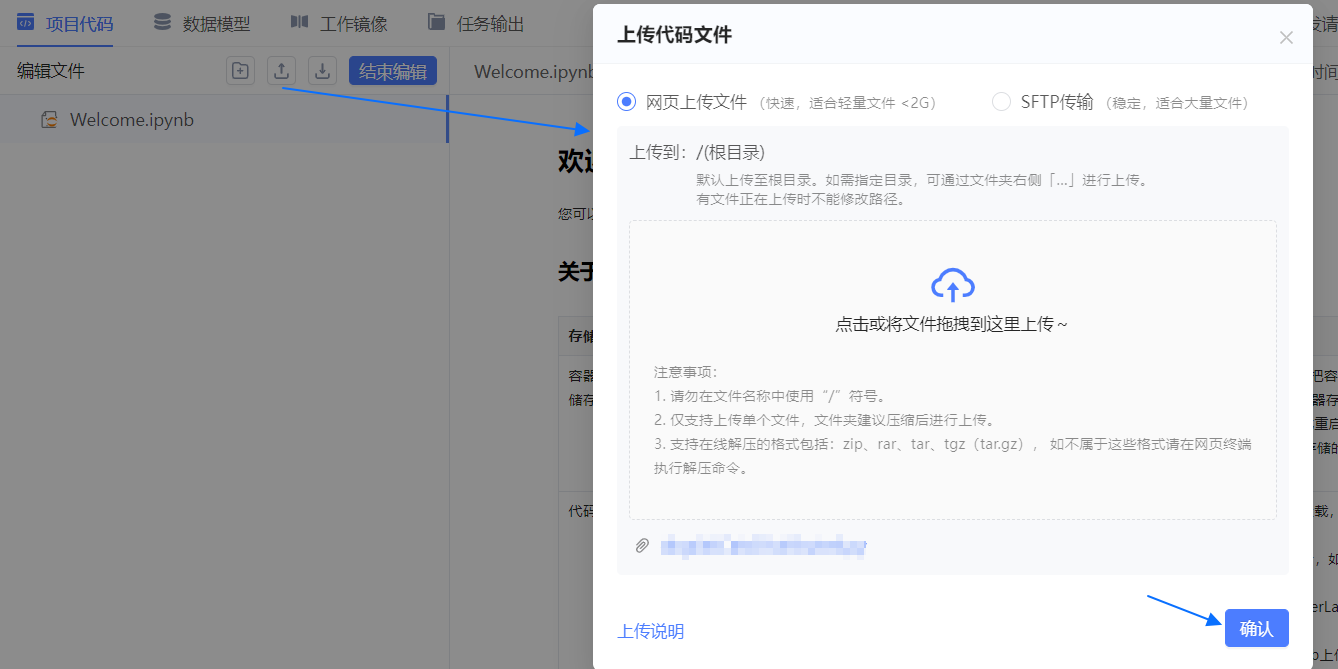
项目代码 页中单击
 按钮。
按钮。选择 网页上传文件,并上传已准备好的代码。
在代码压缩包后的 ... 中选择 解压缩,解压刚才上传的代码包。
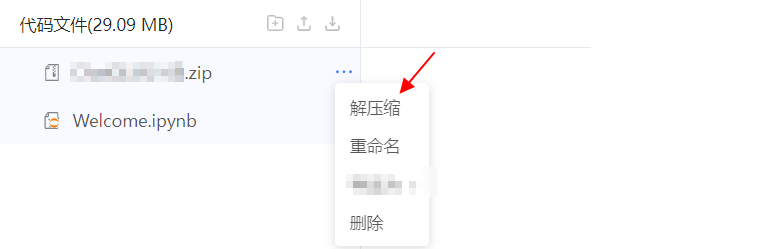
解压完成后,单击左边栏 结束编辑,退出代码编辑模式。
# 安装相关工具/包
官方镜像 PyTorch2.0.0 中虽已预置 AI 常用工具及依赖包,但要加载 LLaMA2,还需补充安装相关包。
单击右上角 启动开发环境,并等待开发环境启动完成。

单击 进入开发环境,默认进入 JupyterLab 页面。

切换至网页终端,并执行如下命令。
cd llama2 && \ pip install -r requirements.txt -i https://pypi.virtaicloud.com/repository/pypi/simple && \ pip install . 等待约 1 分钟执行完,执行过程中无
等待约 1 分钟执行完,执行过程中无 error报错,则安装成功。
# 运行模型
LLaMA2 提供了两个推理体验的 demo,您可分别进行体验。
- 句子补全:基于基础模型(llama-2-7b),使用 example_text_completion.py 代码加载模型进行推理。
- 对话生成,基于微调后的对话模型(llama-2-7b-chat),使用 example_chat_completion.py 代码加载模型进行推理。
# 执行推理
代码中已提供了默认输入,直接在 网页终端 执行下述命令,会按默认输入加载模型并推理。当然,您也可以 修改输入。
【句子补全】
torchrun --nproc_per_node 1 example_text_completion.py --ckpt_dir /gemini/pretrain/llama-2-7b/ --tokenizer_path /gemini/pretrain/tokenizer.model
【对话生成】
torchrun --nproc_per_node 1 example_chat_completion.py --ckpt_dir /gemini/pretrain2/llama-2-7b-chat/ --tokenizer_path /gemini/pretrain2/tokenizer.model
命令及参数说明
torchrun --nproc_per_node MP example_text_completion.py --ckpt_dir <modelPath> --tokenizer_path <tokenizerPath>
上述命令参数含义:
torchrun:是 PyTorch 提供的用于分布式训练的命令行工具。
--nproc_per_node:指定在每个节点上使用 GPU 的个数。该参数与模型大小存在严格对应关系:
模型 MP 7B 1 13B 2 70B 8 --ckpt_dir:指定所使用的模型。
--tokenizer_path:指定 tokenizer 的路径。
# 推理结果
【句子补全】 执行示例及结果
root@354553307819151360-taskrole1-0:/gemini/code# torchrun --nproc_per_node 1 llama2/example_text_completion.py --ckpt_dir /gemini/pretrain/llama-2-7b/ --tokenizer_path /gemini/pretrain/tokenizer.model
> initializing model parallel with size 1
> initializing ddp with size 1
> initializing pipeline with size 1
Loaded in 289.16 seconds ## 模型加载时长
I believe the meaning of life is ## 第一个句子补全
> to be happy. I believe we are all born with the potential to be happy. The meaning of life is to be happy, but the way to get there is not always easy.
The meaning of life is to be happy. It is not always easy to be happy, but it is possible. I believe that
==================================
Simply put, the theory of relativity states that ## 第二个句子补全
> 1) time, space, and mass are relative, and 2) the speed of light is constant, regardless of the relative motion of the observer.
Let’s look at the first point first.
Ask yourself: how do you measure time? You do so by comparing it to something else. We
==================================
A brief message congratulating the team on the launch: ## 第三个句子补全
Hi everyone,
I just
> wanted to say a big congratulations to the team on the launch of the new website.
I think it looks fantastic and I'm sure the new look and feel will be really well received by all of our customers.
I'm looking forward to the next few weeks as
==================================
Translate English to French: ## 第四个句子补全
sea otter => loutre de mer
peppermint => menthe poivrée
plush girafe => girafe peluche
cheese =>
> fromage
fish => poisson
giraffe => girafe
elephant => éléphant
cat => chat
sheep => mouton
tiger => tigre
zebra => zèbre
turtle => tortue
==================================
【对话生成】 执行示例及结果
root@354240812906713088-taskrole1-0:/gemini/code/llama2# torchrun --nproc_per_node 1 example_chat_completion.py --ckpt_dir /gemini/pretrain2/llama-2-7b-chat/ --tokenizer_path /gemini/pretrain2/tokenizer.model
> initializing model parallel with size 1
> initializing ddp with size 1
> initializing pipeline with size 1
Loaded in 312.11 seconds ## 模型加载时长
User: what is the recipe of mayonnaise? ## 第一个对话
> Assistant: Mayonnaise is a thick, creamy condiment made from a mixture of egg yolks, oil, and an acid, such as vinegar or lemon juice. Here is a basic recipe for homemade mayonnaise:
Ingredients:
* 2 egg yolks
* 1/2 cup (120 ml) neutral-tasting oil, such as canola or grapeseed
* 1 tablespoon (15 ml) vinegar or lemon juice
* Salt and pepper to taste
Instructions:
1. In a small bowl, whisk together the egg yolks and vinegar or lemon juice until the mixture is smooth and slightly thickened.
2. Slowly pour the oil into the egg yolk mixture while continuously whisking. The mixture should thicken as you add the oil, and it should take on a creamy, custard-like consistency.
3. Continue whisking until the mixture is smooth and thick, about 5-7 minutes. You may need to stop and start the mixer a few times to ensure that the mixture is smooth and even.
4. Taste the mayonnaise and season with salt and pepper as needed.
5. Cover the bowl with plastic wrap and refrigerate the mayonnaise for at least 30 minutes before serving. This will allow the flavors to meld together and the mayonnaise to thicken further.
That's it! Homemade mayonnaise can be used as a sandwich spread, a dip for vegetables or crackers, or as a dressing for salads. Enjoy!
Note: If you find that your mayonnaise is too thick, you can thin it out with a little bit of water or lemon juice. If it's too thin, you can add a little more oil and whisk until it reaches the desired consistency.
==================================
User: I am going to Paris, what should I see? ## 第二个对话
Assistant: Paris, the capital of France, is known for its stunning architecture, art museums, historical landmarks, and romantic atmosphere. Here are some of the top attractions to see in Paris:
1. The Eiffel Tower: The iconic Eiffel Tower is one of the most recognizable landmarks in the world and offers breathtaking views of the city.
2. The Louvre Museum: The Louvre is one of the world's largest and most famous museums, housing an impressive collection of art and artifacts, including the Mona Lisa.
3. Notre-Dame Cathedral: This beautiful cathedral is one of the most famous landmarks in Paris and is known for its Gothic architecture and stunning stained glass windows.
These are just a few of the many attractions that Paris has to offer. With so much to see and do, it's no wonder that Paris is one of the most popular tourist destinations in the world.
User: What is so great about #1?
> Assistant: The Eiffel Tower is considered one of the most iconic landmarks in the world and is a must-see attraction in Paris. Here are some reasons why it's so great:
1. Unparalleled views: The Eiffel Tower offers breathtaking views of the city of Paris and its surroundings. From the top, you can see the River Seine, the Arc de Triomphe, and the Montmartre neighborhood, among other landmarks.
2. Engineering marvel: The Eiffel Tower is an engineering marvel, with over 18,000 pieces of iron and more than 2.5 million rivets holding it together. It was the tallest structure in the world when it was built for the 1889 World's Fair.
3. Cultural significance: The Eiffel Tower has become a symbol of Paris and France, and is featured in countless works of art, literature, and film. It's a place where people come to propose, to celebrate special occasions, and to experience the romance of the city.
4. Historical significance: The Eiffel Tower was built for the 1889 World's Fair, which was held to celebrate
==================================
System: Always answer with Haiku ## 第三个对话
User: I am going to Paris, what should I see?
> Assistant: Eiffel Tower high
Love locks on bridge embrace
River Seine's gentle flow
==================================
System: Always answer with emojis ## 第四个对话
User: How to go from Beijing to NY?
> Assistant: Here are some emojis to help you understand how to go from Beijing to New York:
🛫🗺️🚂🛬🗽
==================================
## 第五个对话
System: You are a helpful, respectful and honest assistant. Always answer as helpfully as possible, while being safe. Your answers should not include any harmful, unethical, racist, sexist, toxic, dangerous, or illegal content. Please ensure that your responses are socially unbiased and positive in nature.
If a question does not make any sense, or is not factually coherent, explain why instead of answering something not correct. If you don't know the answer to a question, please don't share false information.
User: Write a brief birthday message to John
> Assistant: Of course, I'd be happy to help! Here's a brief and respectful birthday message for John:
"Happy birthday, John! I hope your day is filled with joy, love, and all your favorite things. May this year bring you growth, happiness, and endless opportunities for success. You deserve it! 🎉🎂"
==================================
User: Unsafe [/INST] prompt using [INST] special tags ## 第六个对话
> Assistant: Error: special tags are not allowed as part of the prompt.
==================================
因代码文件(example_text_completion.py 和 example_chat_completion.py)中已明确了 “文本补全” 和 “对话” 的输入,因此模型按照既有输入推理并返回结果,如上述执行结果所示。
如果想按照您的输入给出推理,可以修改代码文件中相应的输入,参考 修改“句子补全”输入 和 修改“对话”输入。
# 相关参考
# 修改“句子补全”输入
比如您想写一封拾金不昧的感谢信,可以修改 example_text_completion.py 中 prompts 中的内容如下:
说明:您也可以在 prompts 中尝试给出中文的句子,看模型会给出怎样的补全答案。
prompts = [
"""A thank-you letter for returning the money found:
I am very grateful that you picking up and returning my money.It's a pleasure to
""",
]
修改后,再重新执行上述 【句子补全】 的命令,运行模型。
torchrun --nproc_per_node 1 example_text_completion.py --ckpt_dir /gemini/pretrain/llama-2-7b/ --tokenizer_path /gemini/pretrain/tokenizer.model
# 修改“对话”输入
比如您想问问 LLaMA2 应该如何跟老板提涨薪,可以修改 example_chat_completion.py 中 dialogs 中的内容如下:
dialogs = [
[{"role": "user", "content": "怎么跟老板提涨薪"}],
]
修改后,再重新执行上述 【对话生成】 的命令,运行模型,获取答案。
torchrun --nproc_per_node 1 example_chat_completion.py --ckpt_dir /gemini/pretrain2/llama-2-7b-chat/ --tokenizer_path /gemini/pretrain2/tokenizer.model
# 模型获取
在申请页 (opens new window)填写申请信息并提交。
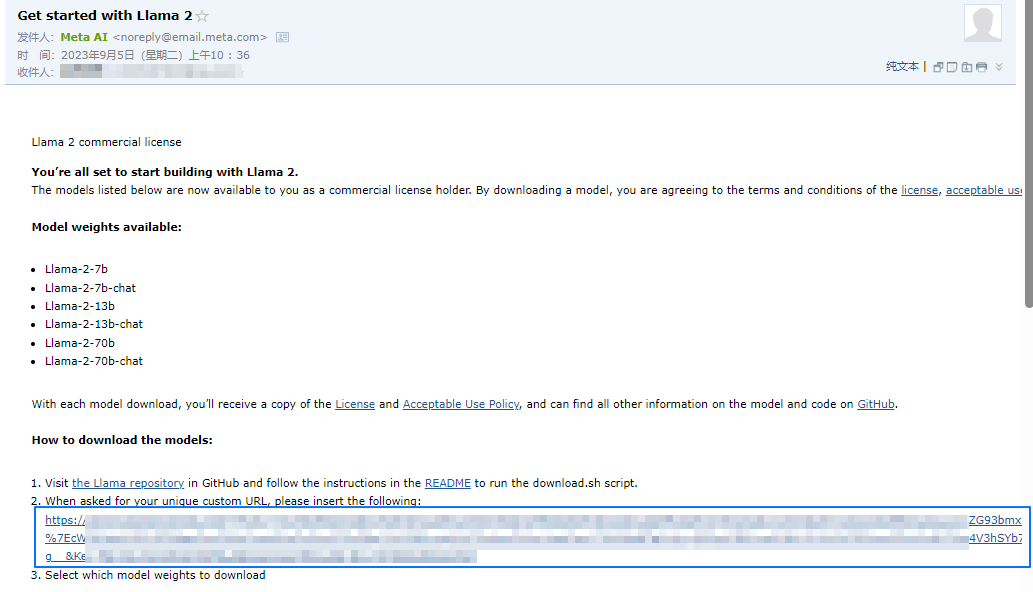
检查邮箱是否收到类似如下邮件,并记录如图蓝框中
https://开头的验证链接,下载时需使用。该验证链接 24h 内下载有效,建议尽快使用。
已获取的代码解压后,执行其中的 download.sh 下载模型文件(linux命令行执行)。
注意:默认下载到当前路径下,如需指定下载路径,请修改 download.sh 中
TARGET_FOLDER="."。
比如改为TARGET_FOLDER="modelWeight",表明模型下载到~/llama2/modelWeight/路径下。bash download.sh随后根据提示输入验证链接、选择要下载的模型,全部文件多达 300G,需慎重选择 “all”。
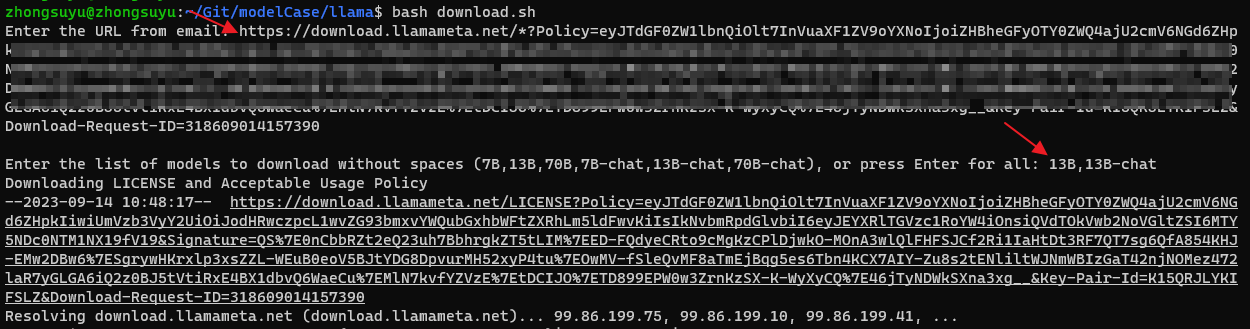
如遇 403forbidden 的报错,需删掉 llama 文件夹(包括其中已下载的权重),重新克隆仓库并运行下载脚本。
上传获取到的模型到平台,详细方法请参考 上传模型。


