部署ChatGLM2-6B
本案例以 “ChatGLM2-6B” 模型为例,指导如何在平台开发环境中部署模型。
ChatGLM2-6B:是一个开源的、支持中英双语的对话语言模型,由清华大学团队开发,旨在改进对话机器人的语言生成质量和逻辑。ChatGLM2-6B 已经在大规模数据集上进行过训练,您可以直接部署、体验与机器人的高质量对话,也可以用自有数据集对其微调,得到自己的专属大模型。详情可参考 ChatGLM2-6B 官方 (opens new window)。
# 创建项目
单击平台项目页右上角的 创建项目,随后在弹框中配置项目的基本信息。
- 项目名称:可自定义,如 “ChatGLM2-6B体验”。
- 项目描述:如 “部署并体验与ChatGLM2-6B对话”。
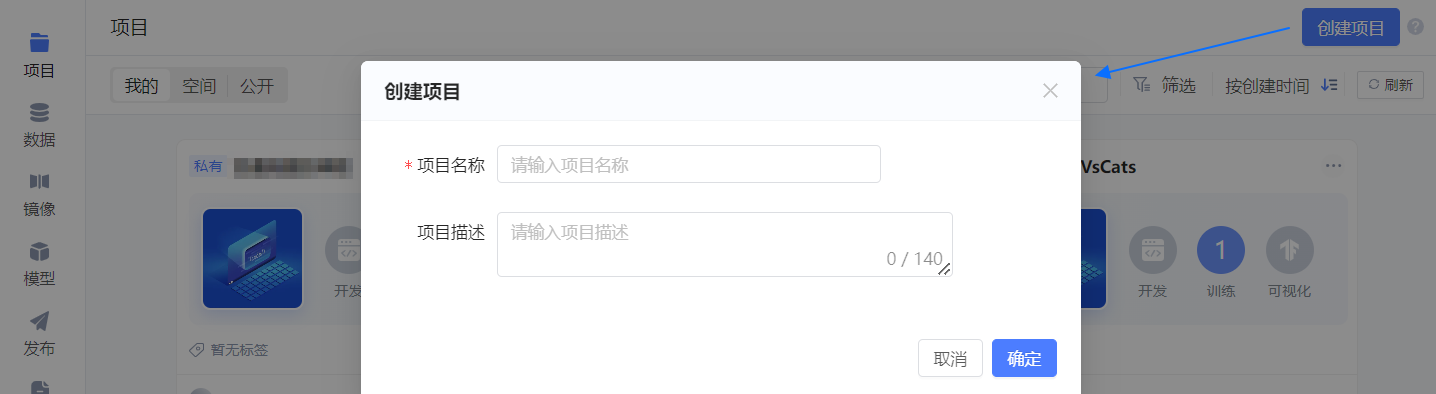
单击 确定,项目创建成功,并进入 初始化开发环境 引导页。
在 初始化开发环境 页中配置如下信息,其他参数保持默认值。
- 资源配置:选择 P1.medium,小于该配置,模型可能加载失败。
- 镜像:选择 公开 镜像 ChatGLM2_6B(作者为 “趋动云小助手”)。
- 数据:选择 社区 > 全部 下的 AdvertiseGen 数据集。
- 模型:选择 公开 下的 chatglm2-6b(作者为 “趋动云小助手”)。
- 自动停止(高级设置 中):选择 2小时。
- 开放端口(高级设置 中):添加 1 个端口用于网页形式访问部署好的 ChatGLM2-6B。内部端口,填写 1025;备注为 “chatglm2-6b 网页形式访问”。
随后单击右下角 我要上传代码,暂不启动,进入 项目代码 页。
# 上传代码
项目代码 页中单击
 按钮。
按钮。选择 网页上传文件,并上传 已获取的代码 (opens new window)。
说明:自行
git clone https://github.com/THUDM/ChatGLM2-6B获取的代码需注意修改代码中的模型路径。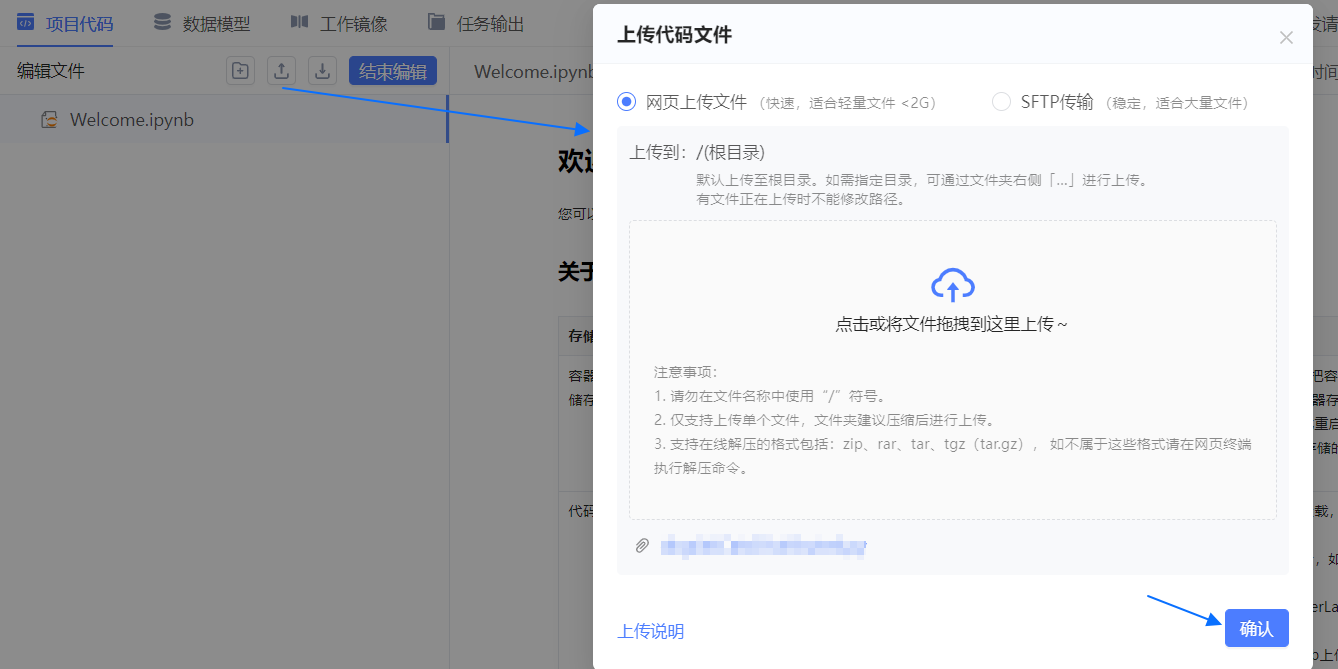
在代码压缩包后的 ... 中选择 解压缩,解压刚才上传的代码包。
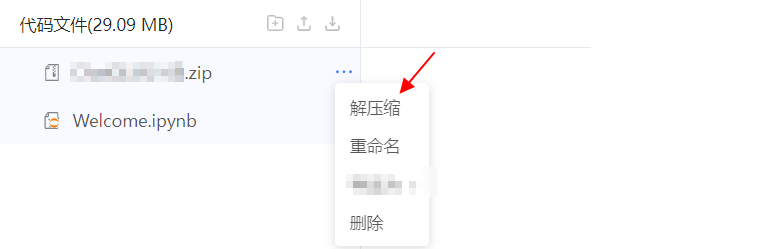
解压完成后,单击 结束编辑,退出代码编辑模式。
# 部署ChatGLM2-6B
单击右上角 启动开发环境,并等待开发环境启动完成。

单击 进入开发环境,默认进入 JupyterLab 页面。

顶部切换至 网页终端。

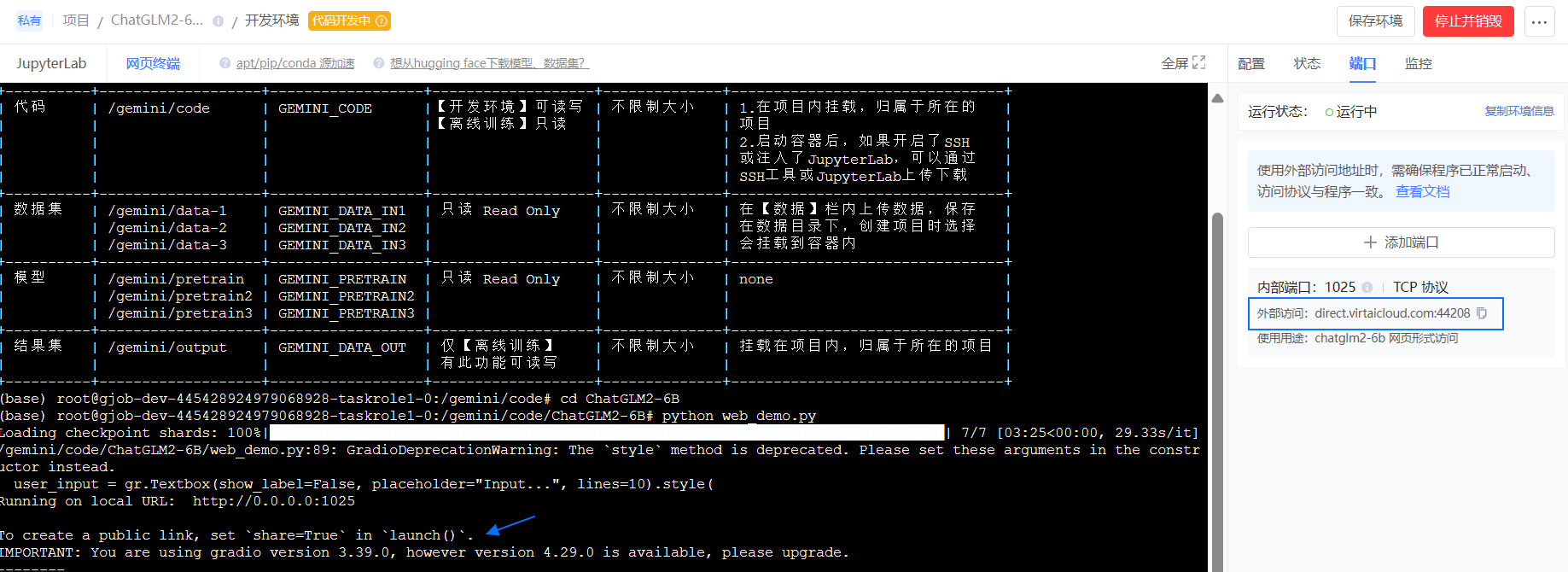
执行如下命令,进入
ChatGLM2-6B目录并部署模型。说明:如果使用您自己获取的代码,则需相应的进入
web_demo.py所在目录执行,可能未必是ChatGLM2-6B目录。cd ChatGLM2-6B python web_demo.py等待系统返回类似信息,则加载成功。
Loading checkpoint shards: 100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 7/7 [01:29<00:00, 12.73s/it] /gemini/code/ChatGLM2-6B/web_demo.py:89: GradioDeprecationWarning: The `style` method is deprecated. Please set these arguments in the constructor instead. user_input = gr.Textbox(show_label=False, placeholder="Input...", lines=10).style( Running on local URL: http://127.0.0.1:15432 Running on public URL: https://bd2a91f942ff33eecf.gradio.live This share link expires in 72 hours. For free permanent hosting and GPU upgrades, run `gradio deploy` from Terminal to deploy to Spaces (https://huggingface.co/spaces)浏览器中输入访问地址,进入 ChatGLM2-6B 问答界面。
返回如下信息,则访问地址为第 5 行的
https://...gradio.live。

返回如下信息,则内网穿透失败,访问地址为
http:外部访问地址。部分浏览器默认为 https 访问,因此可能会失败,可打开浏览器无痕模式再行访问。
在
Input...区域输入您的问题并 提交,等待 ChatGLM 返回给您答案。
Tips:
首次提问,需稍微等待 20s 调取问答程序,然后再返回答案,后续问答无此限制。
单击右下角 Clear History,可清空对话历史。至此,可确认部署成功。
# 其他参考
# 定制代码
若您不使用平台提供的代码,需参考如下描述,修改 web_demo.py 中如下两处信息并保存。
修改模型地址
替换如图所示处THUDM/chatglm2-6b为/gemini/pretrain,/gemini/pretrain为模型在开发环境中默认挂载的地址。

(可选)设置为本地运行该程序
说明:为防止 frpc 内网穿透失败,增加此设置。公网访问某程序,需借助 frcp 进行内网穿透生成公网访问地址,而 frcp 需从国外源下载,可能存在下载失败的情况。
最后一行增加
server_name='0.0.0.0', server_port=xx,修改后形如:demo.queue().launch(share=False, inbrowser=True, server_name='0.0.0.0', server_port=1025)1025为您添加的端口,需根据实际情况填写。

# 部署为命令行方式
以命令行形式加载模型并进行问答测试。
修改 cli_demo.py 中模型的地址,将
THUDM/chatglm2-6b替换为/gemini/pretrain。

切换至 网页终端。
执行如下命令唤醒交互式对话。
python cli_demo.py等待最终
Loading checkpoint shards: 100%且返回用户:字样,如图所示。说明:加载模型前会按顺序找库,优先路径下未安装则 warning 提示,若最终加载成功可忽略该提示。

在
用户:行输入您的问题并回车,等待 ChatGLM 回答您的问题。
ChatGLM:行若有相应信息返回,则环境准备完成。

Tips: 输入 clear 可以清空对话历史,输入 stop 终止程序。
首次提问,需稍微等待 20s 调取问答程序,然后再返回答案,后续问答无此限制。
# 异常处理
- 执行
python web_demo.py加载模型时报错如下。Answer:可能是实例规格选择太小,请更换成更高的实例规格。Loading checkpoint shards: 71%|██████████████████████████████ | 5/7 [01:03<00:26, 13.37s/it]Killed


