ChatGLM2-6B创作广告
本案例以 “ChatGLM2-6B” 模型为例,指导如何使用平台的 离线训练 功能对模型进行强化训练,使其拥有我们想要的能力,本例主要是使用大量广告词来对 ChatGLM2-6B 进行专项训练,使其具备广告词创作的能力。
其他模型的强化训练步骤类似,可参考本案例操作。
# 前提条件
已体验 部署ChatGLM2-6B。
# 查看原模型的广告生成
了解原始 ChatGLM2-6B 的广告词生成能力,以便与专项训练后的能力形成对比。
进入 ChatGLM2-6B体验 的项目详情。
进入 ChatGLM2-6B体验 项目的开发环境。

顶部切换至 网页终端。

网页终端中执行如下命令,创建一个 json 文件并填入想生成广告的衣物的特性(content)。
touch /gemini/code/test.json echo '{"content": "类型#裙*材质#网纱*图案#蝴蝶结*裙下摆#层叠*裙长#半身裙*裙衣门襟#系带", "summary": "层叠网纱,仙气飘飘,却不会过于膨胀。腰间的蝴蝶结系带,恰到好处的增添了柔美感。膝盖以下,长度刚刚好的半身裙,比起“一览无遗魅力尽显”,专注于“完美隐藏”"}' > /gemini/code/test.json执行如下命令进行推理。
使用自己准备的代码,需相应修改第一行中
main.py的路径。torchrun --standalone --nnodes=1 --nproc-per-node=1 /gemini/code/ChatGLM2-6B/ptuning/main.py \ --do_predict \ --validation_file /gemini/code/test.json \ --test_file /gemini/code/test.json \ --model_name_or_path /gemini/pretrain \ --output_dir /gemini/code/adgen01 \ --overwrite_cache \ --prompt_column content \ --response_column summary \ --overwrite_output_dir \ --max_source_length 64 \ --max_target_length 64 \ --per_device_eval_batch_size 1 \ --predict_with_generate \ --pre_seq_len 128 \ --quantization_bit 4最终返回如下信息,则执行完成。
08/11/2023 15:30:42 - DEBUG - jieba - Prefix dict has been built successfully. 100%|██████████████████████████████████████████████████████████████████████████████████| 1/1 [00:00<00:00, 1.57it/s] ***** predict metrics ***** predict_bleu-4 = 0.2325 predict_rouge-1 = 8.1633 predict_rouge-2 = 0.0 predict_rouge-l = 6.7797 predict_runtime = 0:00:44.41 predict_samples = 1 predict_samples_per_second = 0.023 predict_steps_per_second = 0.023 root@3c6cecd2d1ea73c792d2eea7b32b3922-taskrole1-0:/gemini/code#使用 JupyterLab 查看
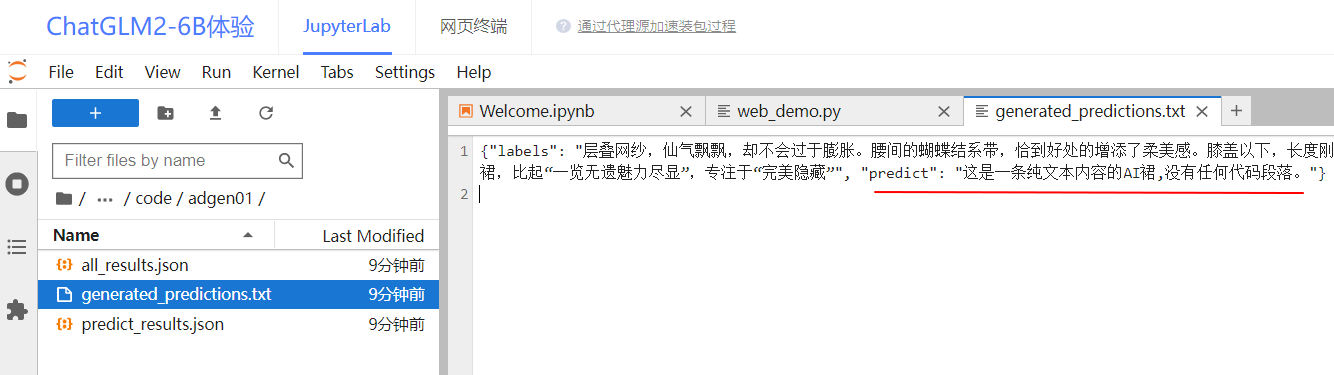
/gemini/code/adgen01/generated_predictions.txt中的predict字段。
该字段即是原始模型根据类型#裙*材质#网纱*图案#蝴蝶结*裙下摆#层叠*裙长#半身裙*裙衣门襟#系带生成的广告词。
单击右上角 停止 按钮,停止开发环境。
# 提交离线训练
使用已挂载到项目的数据(即 AdvertiseGen 数据集中的 dev.json 和 train.json 文件)对 ChatGLM2-6B 进行专项训练。文件中包含标记好的各物品及其特征(content)和对应的标准广告词(summary),让 chatglm2-6b 根据输入(content)生成一段广告词并与标答(summary)比对,从而不断修正优化,直到最终能够根据输入生成较为贴切的广告词。
单击顶部项目名,回到项目详情页。

单击项目详情页右上角 离线任务,进入离线任务页。
单击右上角 提交任务 按钮。
参考如下说明配置任务基本信息,其他参数保持默认值。
- 任务名称:自定义,如:chatglm2-6B-train。
- 代码:挂载。
- 数据:保持默认。
- 模型:保持默认。
- 任务模式:选择 单机任务。
- 资源配置:选择 高级版 的 P1.large。
- 启动命令:填写如下启动命令,系统将在创建好训练环境后通过如下命令启动训练。上述命令指执行 main.py 脚本启动训练,其中,
torchrun --standalone --nnodes=1 --nproc-per-node=1 /gemini/code/ChatGLM2-6B/ptuning/main.py \ --do_train \ --train_file $GEMINI_DATA_IN1/train.json \ --validation_file $GEMINI_DATA_IN1/dev.json \ --model_name_or_path $GEMINI_PRETRAIN \ --output_dir $GEMINI_DATA_OUT/adgen-chatglm2-6b-pt-128-2e-2 \ --preprocessing_num_workers 10 \ --prompt_column content \ --response_column summary \ --overwrite_cache \ --overwrite_output_dir \ --max_source_length 64 \ --max_target_length 128 \ --per_device_train_batch_size 1 \ --per_device_eval_batch_size 1 \ --gradient_accumulation_steps 16 \ --predict_with_generate \ --max_steps 100 \ --logging_steps 10 \ --save_steps 50 \ --learning_rate 2e-2 \ --pre_seq_len 128 \ --quantization_bit 4--train_file:指定训练数据为$GEMINI_DATA_IN1/train.json。--validation_file:指定验证数据为$GEMINI_DATA_IN1/dev.json。--model_name_or_path:预训练模型为$GEMINI_DATA_IN2中的 chatglm2-6b 模型。--output_dir:指定训练结果保存在$GEMINI_DATA_OUT目录下。
- 工作镜像:保持默认。
单击 提交,返回 离线任务 页面。
等待任务状态为 成功 ,则训练完成。
# 查看训练结果
将训练结果导出为模型,并将其挂载到开发环境中,在开发环境中加载训练后的模型并用其对 test.json 进行推理,看看经过专项训练后的模型是否会生成更好的广告词。
# 【A】导出为模型
项目详情中切换到 任务输出 页。
单击右上方 导出,随后勾选文件夹,并单击 导出为模型。
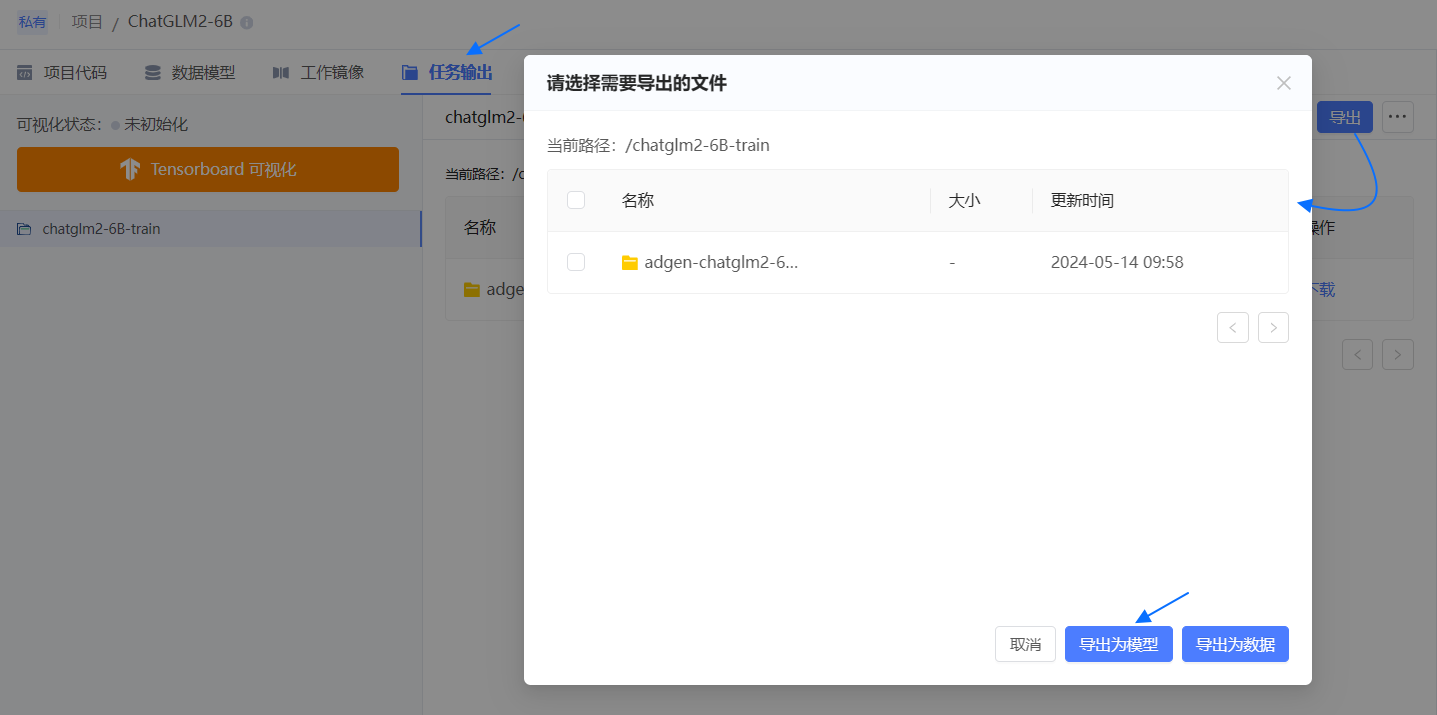
填写模型导出信息。
- 模型名称:可自定义,如 chatglm2-6b-AD。
- 模型描述:保持默认。
- 模型文件:保持默认。
- 模型格式:保持默认。
- 标签:保持默认。
- 公开性:保持默认。
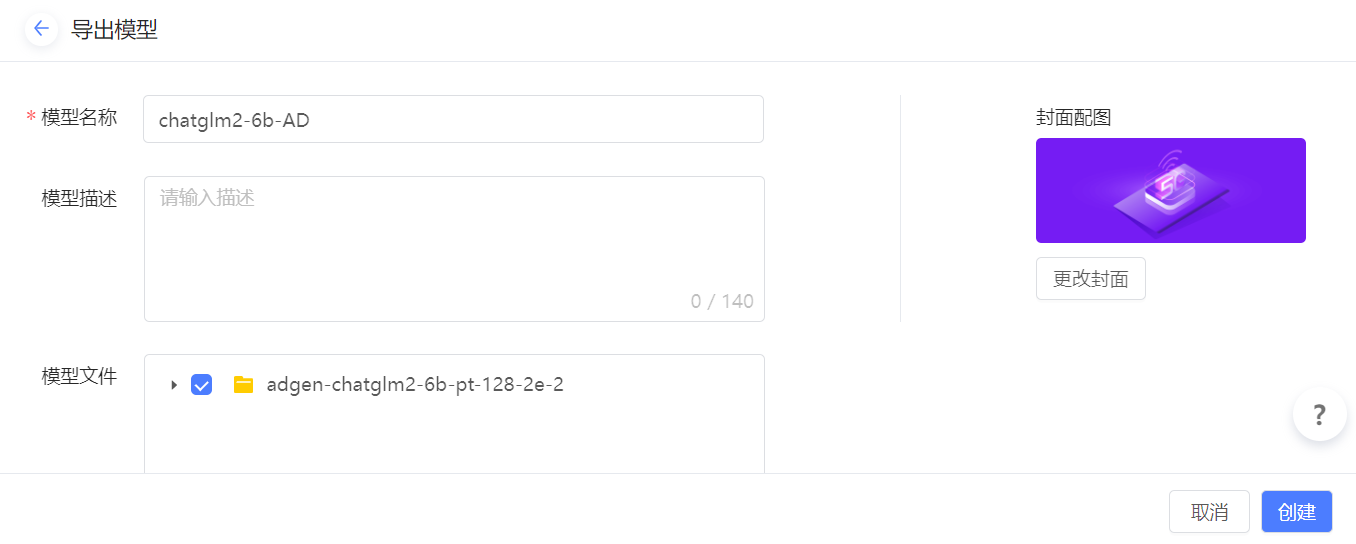
单击 创建,等待导出成功的提示。
# 【B】挂载到开发环境
项目详情右边栏的 配置 页中,单击模型的 修改。
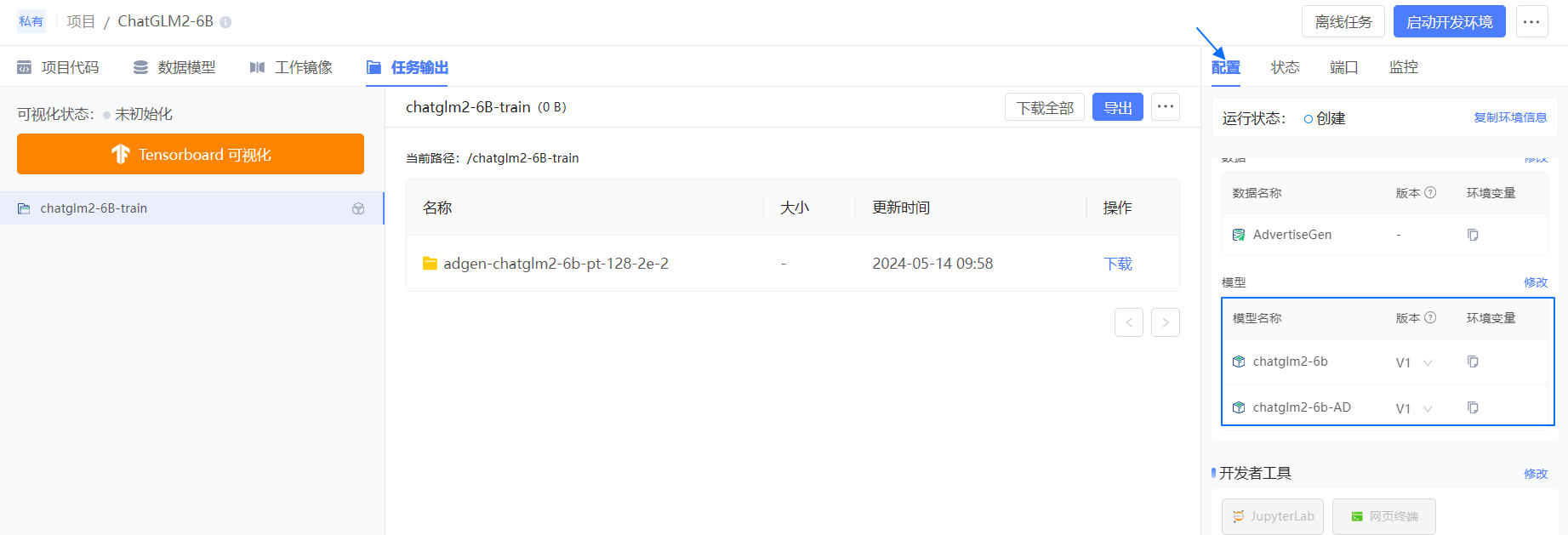
选择刚才导出的模型 chatglm2-6b-AD,并单击 确认。
单击右上角 启动开发环境,等待开发环境启动完成。

# 【C】推理
单击项目详情页右上角 进入开发环境。
切换到 网页终端。
执行如下命令,使用训练后的模型推理此前推理过的
test.json。torchrun --standalone --nnodes=1 --nproc-per-node=1 /gemini/code/ChatGLM2-6B/ptuning/main.py \ --do_predict \ --validation_file /gemini/code/test.json \ --test_file /gemini/code/test.json \ --model_name_or_path /gemini/pretrain \ --ptuning_checkpoint /gemini/pretrain2/adgen-chatglm2-6b-pt-128-2e-2/checkpoint-100 \ --output_dir /gemini/code/adgen02 \ --overwrite_cache \ --prompt_column content \ --response_column summary \ --overwrite_output_dir \ --max_source_length 64 \ --max_target_length 64 \ --per_device_eval_batch_size 1 \ --predict_with_generate \ --pre_seq_len 128 \ --quantization_bit 4等待执行完成。
查看
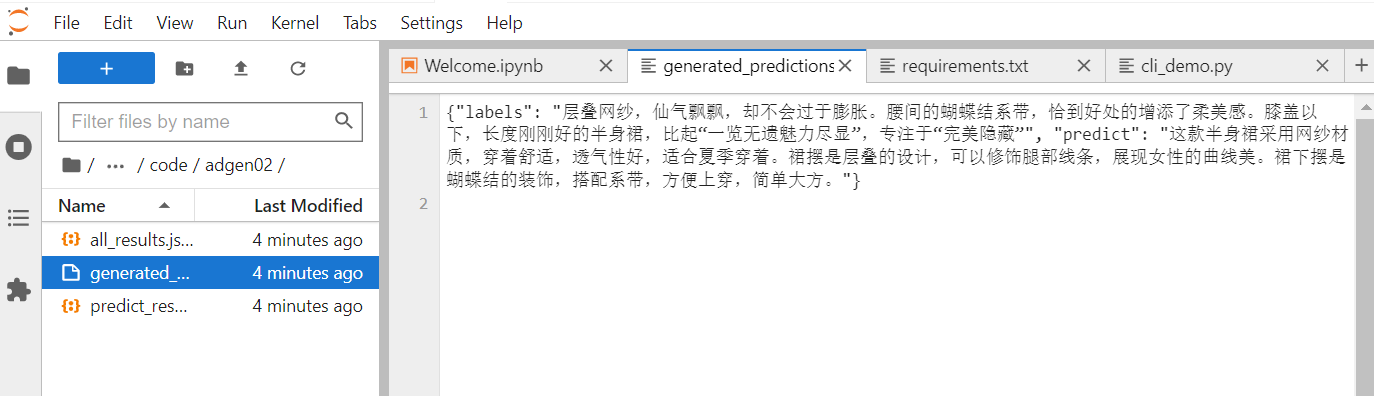
/gemini/code/adgen02/generated_predictions.txt中的predict字段。
该字段即为训练后的模型根据类型#裙*材质#网纱*图案#蝴蝶结*裙下摆#层叠*裙长#半身裙*裙衣门襟#系带生成的广告词。
# 【D】结果对比
/gemini/code/ 路径下的 adgen01、adgen02 分别是原始模型的推理结果和强化训练后的模型推理结果,对比它们 generated_predictions.txt 中的 predict 字段。
- 原始模型:这是一条纯文本内容的AI裙,没有任何代码段落。
- 强化训练后:这款半身裙采用网纱材质,穿着舒适,透气性好,适合夏季穿着。裙摆是层叠的设计,可以修饰腿部线条,展现女性的曲线美。裙下摆是蝴蝶结的装饰,搭配系带,方便上穿,简单大方。
可见,针对同一个输入,强化后的模型生成的广告词更加流畅具有美感,和训练所用数据中的 summary 的风格比较贴近,而原始模型生成的广告词则生硬甚至无逻辑。


