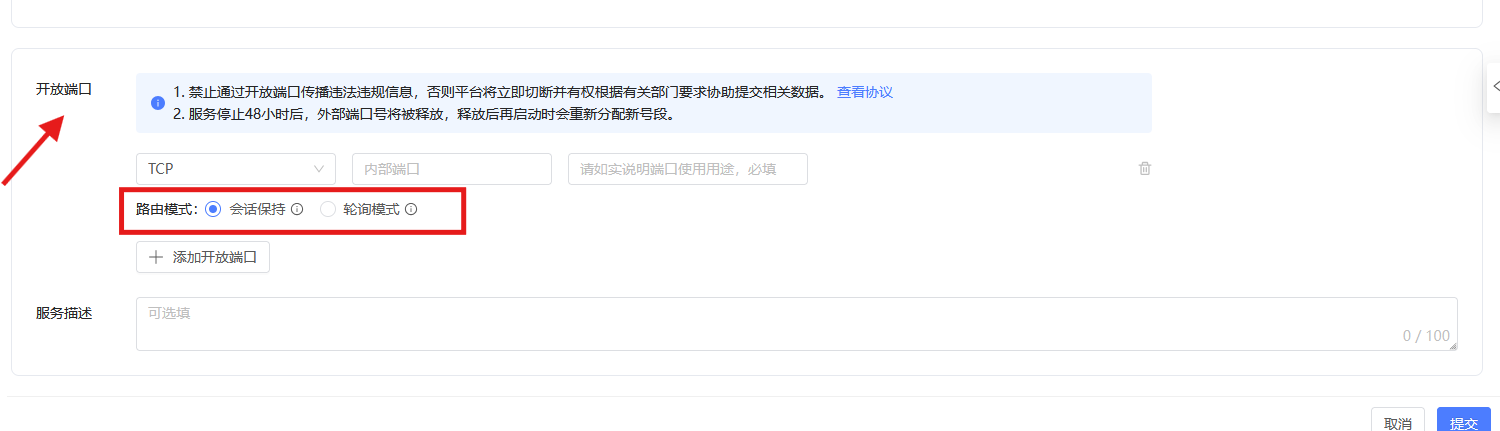
设置路由模式
更新时间:
推理服务端口有两种路由模式:会话保持、轮询模式。用户可根据应用场景设置相应的路由模式。创建推理服务时,默认为会话保持。更新推理服务时支持修改路由模式,服务处于任何状态即使运行中,也允许修改。
# 路由模式对比
| 对比维度 | 会话保持 (Session Affinity) | 轮询模式 (Round-Robin) |
|---|---|---|
| 优势 | 1.确保上下文连续。2.提高缓存命中率。3.减少重复计算。 | 1.请求均匀分发。2.支持高并发扩展。3. 更易结合分布式缓存。 |
| 核心适用场景 | 有状态推理(LLM 多轮对话、流式推理)、本地缓存依赖 | 无状态推理(图像分类、单次 NLP 任务)、分布式缓存场景 |
| Latency | 低 (本地缓存复用) | 高 (分布式缓存网络开销) 或低 (无状态时) |
| 负载均衡效果 | 差 (易过载) | 好 (请求均匀时) |
| 可用性 | 低 (实例故障影响会话) | 高 (实例故障影响单个请求) |
| 弹性扩展 | 差 (新增实例仅接新会话) | 好 (新增实例立即分担流量) |
| 架构复杂度 | 低 (无需分布式缓存) | 高 (需维护分布式缓存一致性) |
| 典型推理服务示例 | vLLM 本地 KV 缓存的 LLM 对话、实时视频流式推理 | ResNet 图像分类、BERT 文本分类、分布式 KV 缓存的 LLM |
| 风险/限制 | 1.单实例可能过载。2.扩缩容时会话迁移复杂。3.宕机时存在会话丢失风险。 | 1.无法保持上下文连续性。2.依赖外部分布式缓存时,增加延迟。 |
| 实践建议 | 1.设置合理会话 TTL:通常 10–30 分钟,避免实例长期占用。2.配置最大会话数阈值:防止单实例过载,例如 GPU 单卡可承载 500 会话。3.监控指标:在应用层统计会话数、单实例负载、缓存命中率、请求延迟等指标。4.扩缩容:根据 CPU/GPU 利用率或活跃会话数动态调整副本数量,并在调整过程中通过应用层 Draining 平滑下线旧副本,确保会话连续性。5.故障回退(Fallback):副本宕机时,将会话迁移至其他副本或重建上下文。 | 1.均衡分发请求:默认轮询,在应用层可结合最少连接策略优化延迟。2.配合分布式缓存:上下文和缓存存储在外部,避免依赖本地副本。3.监控指标:在应用层记录整体 QPS、平均响应时间等指标。4.扩缩容:根据监控数据动态调整副本数量,确保资源合理利用。调整副本数量时,无需考虑会话绑定,可快速生效。5.高并发优化:根据延迟和负载调整副本权重或连接策略。 |
# 操作步骤
1.点击 推理服务 悬浮栏,进入推理服务页面。
2.下拉页面,在开放端口处选择 路由模式。