体验一键提交分布式训练
更新时间:
离线训练相较开发环境,可为您提供更快的训练速度,支持分布式多机多卡训练,训练结果可持久化保存。
本节以训练猫狗识别模型为例,将猫狗识别训练代码改为支持分布式,为您介绍如何使用平台进行分布式训练,得到一个猫狗识别模型。
# 前提条件
已 【下载代码包】 (opens new window),提取代码包中的 dogsVsCatsDistributed.py 文件,本次体验需使用。
说明:进行分布式训练要求您的模型训练代码必须是支持分布式的。
# 创建项目
单击平台项目页右上角的 创建项目,随后在弹框中配置项目的基本信息。
- 项目名称:DogsVsCatsDist
- 项目描述:猫狗识别模型的分布式训练
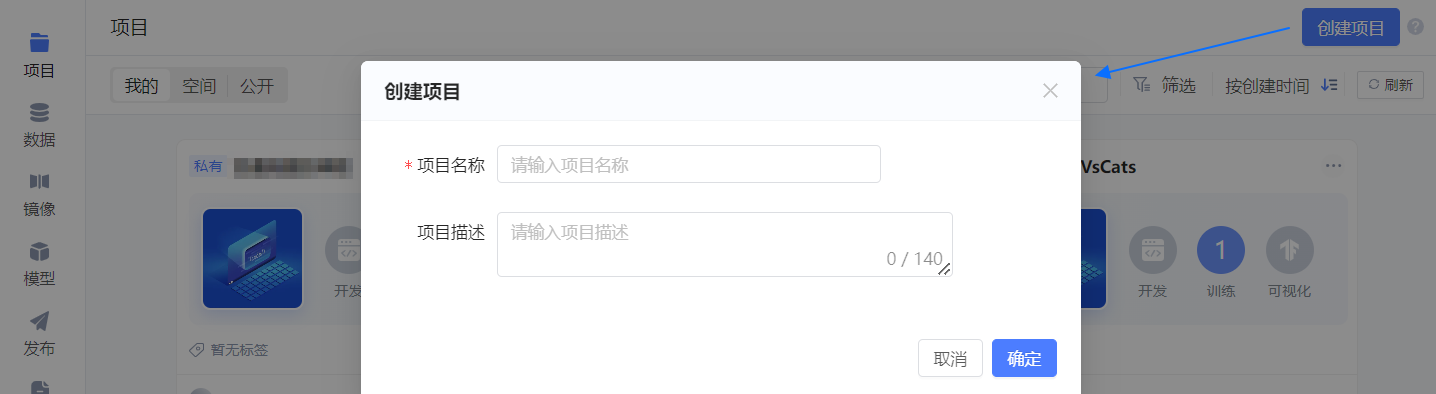
单击 确定,项目创建成功,并进入 初始化开发环境 引导页。
配置如下两项。
- 资源配置:选择 B1.medium。
- 镜像:选择 pytorch 版本为 1.8 及以上的官方镜像,如 PyTorch1.10.1-Conda3.8。
随后单击右下角 我要上传代码,暂不启动,进入 项目代码 页。
# 上传代码
- 项目代码 页中单击
 按钮。
按钮。 - 选择 网页上传文件,并上传
dogsVsCatsDistributed.py文件。
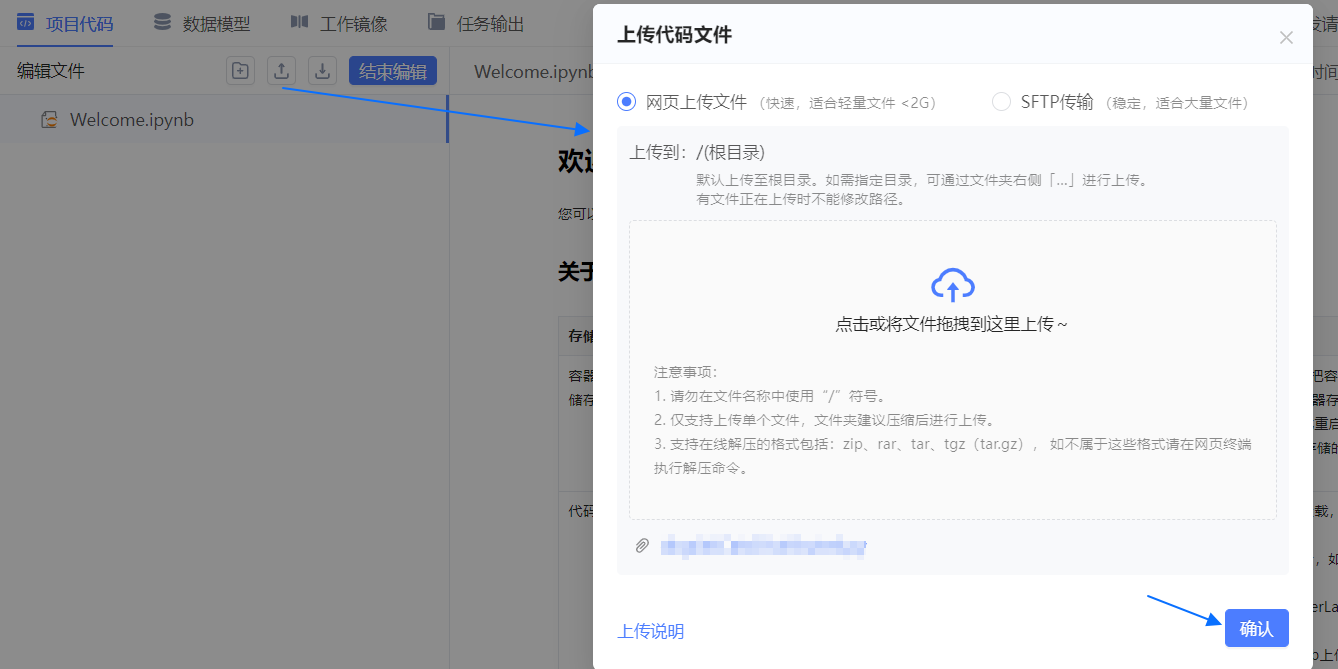
- 单击 结束编辑,退出代码编辑模式。
# 提交离线训练
单击项目详情页右上角 离线任务,进入离线任务页。

随后单击右上角 提交任务。
配置如下基本信息,未提及的参数保持默认值。
任务名称:定义为 DogsVsCats_dist01,您也可以自定义。
数据:选择 公开 下的 ImageNet_ILSVRC2012_few(作者为“趋动云小助手”)。
任务模式:选择 自定义分布式任务。
资源配置:配置训练所需的资源,配置 任务角色1 如下表所示。
说明:表格中仅给出体验的配置示例,您也可根据自身需求自定义。
参数 配置 实例个数 2 资源规格 选择 GPU 型的 B1.medium,也可按照 1 GPU、10GB 单GPU显存、4 CPU、6 内存选择其他规格。启动命令 python -u $GEMINI_RUN/dogsVsCatsDistributed.py -a resnet18 --batch-size 64 --epochs 3 --dist-url "tcp://$GEMINI_IP_taskrole1_0:$GEMINI_taskrole1_0_http_PORT" --dist-backend 'nccl' --multiprocessing-distributed --world-size 2 --rank $GEMINI_CURRENT_TASK_ROLE_CURRENT_TASK_INDEX $GEMINI_DATA_IN1/ImageNet_ILSVRC2012_3G
其中,命令头部python3仅为示例,实际场景中取决于您用于训练的镜像中安装的 python 版本。
命令中的参数由训练代码dogsVsCatsDistributed.py定义,在此稍作解释:- num_epochs 表示训练周期,即训练时遍历该数据集几遍。
- num_workers 表示当前节点数。
- rank 表示当前节点的编号,使用固定的环境变量,从 0 开始计算,当前任务有两个节点,则节点 1 编号为 0,节点 2 编号为 1。
- data_dir 表示训练数据的来源。
- batch_size 表示更新内部模型参数之前要处理的样本数。
- train_dir 表示训练结果存储的目录。
- world-size 表示训练实例数量。
上述命令中的$GEMINI_RUN、$GEMINI_DATA_IN1、$GEMINI_CURRENT_TASK_ROLE_CURRENT_TASK_INDEX和$GEMINI_DATA_OUT是平台为您提供的环境变量。
单击 提交 按钮,提交当前训练任务。
# 查看结果
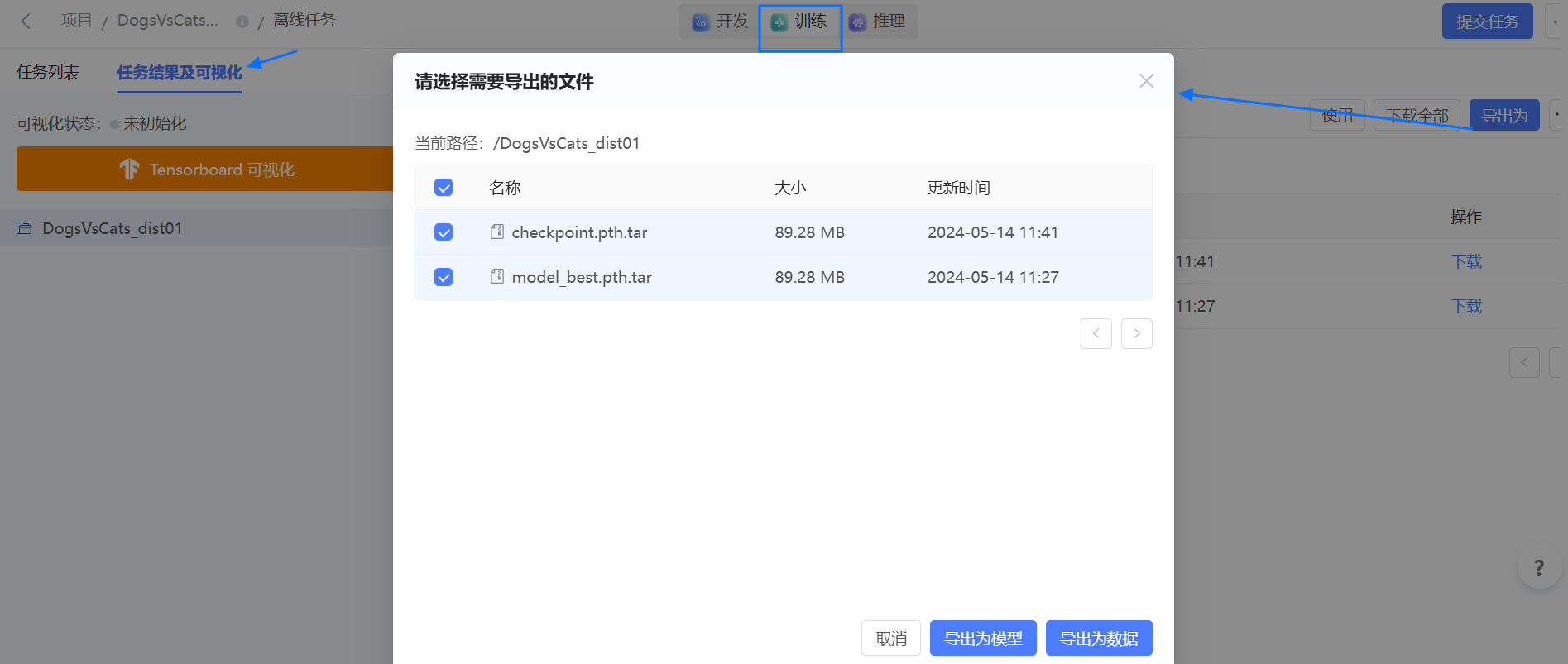
在项目页左侧导航栏中选择 结果,进入 任务结果 页,查看训练任务的输出、或从训练结果导出模型。
# 异常处理
- 训练失败,且报错
RuntimeError: NCCL error in: ../torch/csrc/distributed/c10d/ProcessGroupNCCL.cpp:1269, invalid usage, NCCL version 2.17.1。
解决方法:可能是您选择的镜像中 nccl 版本过低,可更换其他镜像再次尝试,如 PyTorch1.12.1-Conda3.9、PyTorch1.10.0、PyTorch1.9.1-Conda3.8、torch1.8.2-cpu-ubuntu20.04、PyTorch1.8.0 等。


